在上一篇文章《【复盘】如何在资源不足的情况下从 0 到 1 做出一款金融科技产品》1中提到了我使用 KANO 模型来进行需求的一个排序。就有同学让我说下如果通过 KANO 模型来计算优先级,本来说上周安排,但是不好意思,我鸽了……

KANO 模型
提起大名鼎鼎的 KANO 模型,可能从事 PM 这个职业的或者励志从事这个行业的小伙伴都不会陌生。我也曾经在多个文章中提到过 KANO 模型。
作为东京理工大学 Noriaki Kano 教授在 1980s 提出的一种对用户需求进行分类和排序的定性工具,他讲顾客偏好分成了五类:
- 必备型需求:单地说,这些都是客户期望的要求,并且被认为是理所当然的。做得好的时候,顾客是中立的,做得不好的时候,顾客是非常不满意的。Kano 最初称这些为“ Must-be’s ”(「必须的」) ,因为它们是必须包括在内的要求,也是进入市场的门槛。也是我们经常说的「痛点」。客户认为没必要说明,产品也必须要做到的!
- 期望型需求:与客户的满意度正相关,满足时客户会满意,不满足时客户会不满意。一般客户可以明确提出来。这些需求是客户期待的内容。
- 魅力型需求:是产品给客户提供的惊喜型需求,这个需求的满足将让客户的满意度大幅提升,但是即使没有满足,客户也不会感到不满意。(客户自己也不知道自己有这个需求)
- 无差异需求:这个需求满足或者不满足都不会让客户对产品的满意度发生变化。
- 反向型需求:正如文字表面的意思,这个需求刚好与用户的满意度反向相关,如果满足了这个需求,则客户的满意度将会下降。
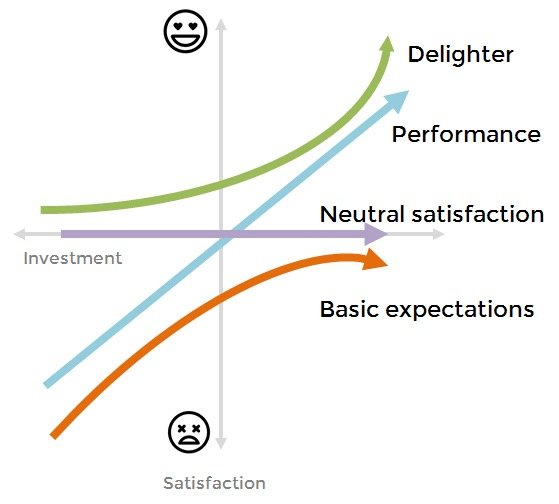
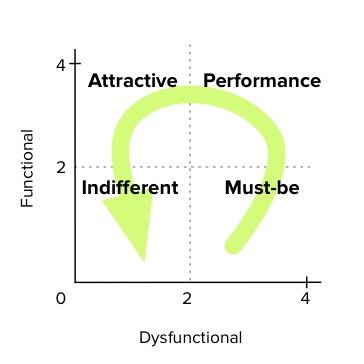
由于客户已经习惯了新功能,而且竞争对手也在追赶。随着时间和市场的变化,很多魅力型、期望型的需求会变化为必备型需求(甚至是反向型需求)的一部分,比如手机的拍照、APP、导航等等。所以对于客户需求的调研要持续进行,以确定是否会产生新的需求。
举个例子:iPhone X 面试的时候,我们觉得它的刘海屏真 NB,但是到了现在Android 手机都已经开始「水滴屏」、「挖孔屏」,但 iPhone 还在坚持的「刘海屏」显然不会成为 iPhone 的期望型需求或者魅力型需求,很多人都在骂 iPhone(显然已经变成了「反向型需求」)。
如何使用 KANO 模型
上边说的这些,其实很多人都知道。随便百度下就可以了。但是具体如何使用 KANO 模型指导工作呢?这里主要用到的就是 Kano questionnaire (KANO 调查问卷)。
要说明的是,KANO 模型有个显著的问题:KANO 模型仅仅关注的是产品性能和用户满意度的非线性关系,只衡量了产品功能对于用户的价值,并没有衡量实现该功能对于企业的收益和成本(商业价值)。
也就是说,当你的产品目标是提升用户满意度的时候,才适合 KANO 模型来进行优先级排序。
Kano questionnaire 一般是由一对问题来组成:
- 当满足了这个需求时,客户觉得如何?
-
当没有这个功能时,客户觉得如何?
针对每一对问题,都不应该让客户开放式的回答,而是应该通过一些非常具体的选项来得到答案:
I like it 我喜欢
I expect it 我希望如此
I am neutral 我是中立的
I can tolerate it 我可以忍受
I dislike it 我不喜欢它
根据我们收集到的问题结果,我们可以制作一个 KANO 评价表:
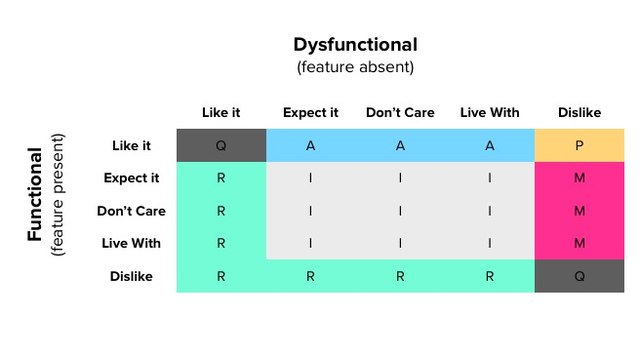
其中:
A:魅力型需求
O:期望型需求
M:必备型需求
I:无差异性属性
R:反向结果
Q:可疑结果(一般不会出现,除非是调查的问题或者客户理解出现了问题,或者有人在瞎填……)
这里延伸一个问题:考虑到我们是从喜欢/不喜欢两个方面问一件事,那么可能存在这样一种情况:
- 有人没有完全理解我们描述的问题和特征;
- 我们的建议实际上和他们想要的恰恰相反
针对这种情况,Fred Pouliot 修订了评价表
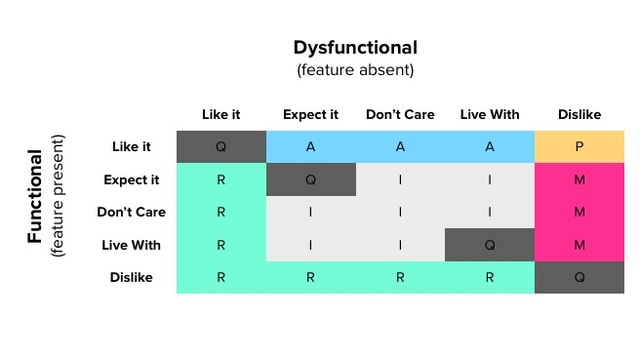
将(2,2)和(4,4)处也改成了 Q
在汇总了所有用户的有效问卷后,我们需要针对某一个需求点进行比例分析,分别得出这个需求点中客户的 A\O\M\I\R\Q 所占的比例,比例值最大对应的类别就是对应功能的分类类别了。
比如 我曾经之前在 P2P 行业针对某一功能点做过的调研数据:
A:15.6%
O:40.1%
M:37.5%
I:1.5%
R:4.5%
Q:0.8%
显然占比最高的是 O (期望型需求)。
那么问题来了,如果几个需求都是一个类别,那么怎么区分优先级呢?这时候我们可以引入 Better-Worse 系数来进行分析。Better-Worse 系数表示的是某个功能可以增加或者消除不喜欢的影响程度。
Better-Worse 系数公式如下:
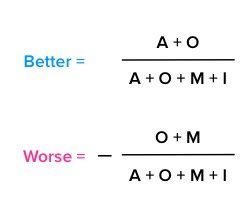
通过计算,每一个需求点都会得到 Better/SI 和 Worse/DSI 两个系数。其中 Better/SI 被理解为增加后的满意系数,数值通常为正数。代表如果提供某种功能属性的话,用户满意度会提升;正值越大/越接近1,表示对用户满意上的影响越大,用户满意度提升的影响效果越强,上升的也就更快。Worse/DSI 则可以被叫做消除后的不满意系数。其数值通常为负,代表如果不提供某种功能属性的话,用户的满意度会降低;值越负向/越接近-1,表示对用户不满意上的影响最大,满意度降低的影响效果越强,下降的越快。
既然有了两个系数,我们就可以做一个平面直角坐标系了。
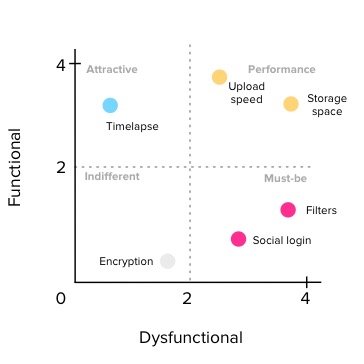
根据这个坐标系,我们可以按照如下排序规则进行排序:必须 > 期望 > 魅力 > 无差异
对于在同一象限中的功能点,以 Better系数/|Worse 系数|的大小排序,越大越靠前。
最后
上边说到了,KANO 模型仅仅关注的是产品性能和用户满意度的非线性关系,并没有衡量实现该功能对于企业的收益和成本(商业价值)。在实际使用上,我之前还推荐过《需求管理之价值 vs 复杂度矩阵》,通过价值和成本的对比进行需求的排序。
不过 KANO 和价值 VS 复杂度矩阵都是一种工具,具体怎么用还得在实际业务中选择最合适的。
References
- 《【复盘】如何在资源不足的情况下从 0 到 1 做出一款金融科技产品》: https://mp.weixin.qq.com/s/b5GMqMj9cKk40nGerkjYqQ ↩