原文标题:PYTHON FOR PRODUCT MANAGERS - PART 2: USING PANDAS FOR DATA ANALYSIS
原文地址:https://productmetrics.net/blog/python-for-product-managers-part-2/1
原文作者:Joshua
翻译:张小璋 Sylvain Zhang

在本系列的第一部分2中,我们研究了如何安装 Python,设置 Jupyter Notebooks以及简单示范了如何在数据分析工作中使用 Python 。
正如我们在上一篇文章中看到的那样,Pandas 是一个非常强大的 Python 数据分析模块。在本部分中,我们将介绍如如何用它来加载和探索某些数据。
导入 Pandas
导入 Pandas 模块是第一步,这是一个非常容易的步骤。一个常见的做法似乎是导入 pandas 模块并为它设置一个别名「pd」——我猜想这只是为了节省一些键入的时间。
要导入 Pandas 模块,你只需要在你的脚本或者 Jupyter 头部包含以下代码:
import pandas as pd
如果你正在使用 Jupyter Notebooks ,并希望在 Jupyter 中可视化显示,则通过以下代码导入 Pandas,启用内嵌可视化并设置一些默认样式:
# 在 Jupyter Notebooks 中内嵌显示图形和图标
%matplotlib inline
# 导入一些库
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
# 设置一些默认的绘图样式使图标看起来更 nice
matplotlib.rcParams['figure.figsize'] = (20.0, 10.0)
plt.style.use('bmh')
我喜欢bmh 的风格,但其实还有很多风格可供选择,所以你可以去看下其它的样式3
了解 Pandas DataFrame
Pandas 中的主要数据结构是 DataFrame4,你可以把它视作 Excel 表格或者数据库表。他是一个包含列和行的数据集合。
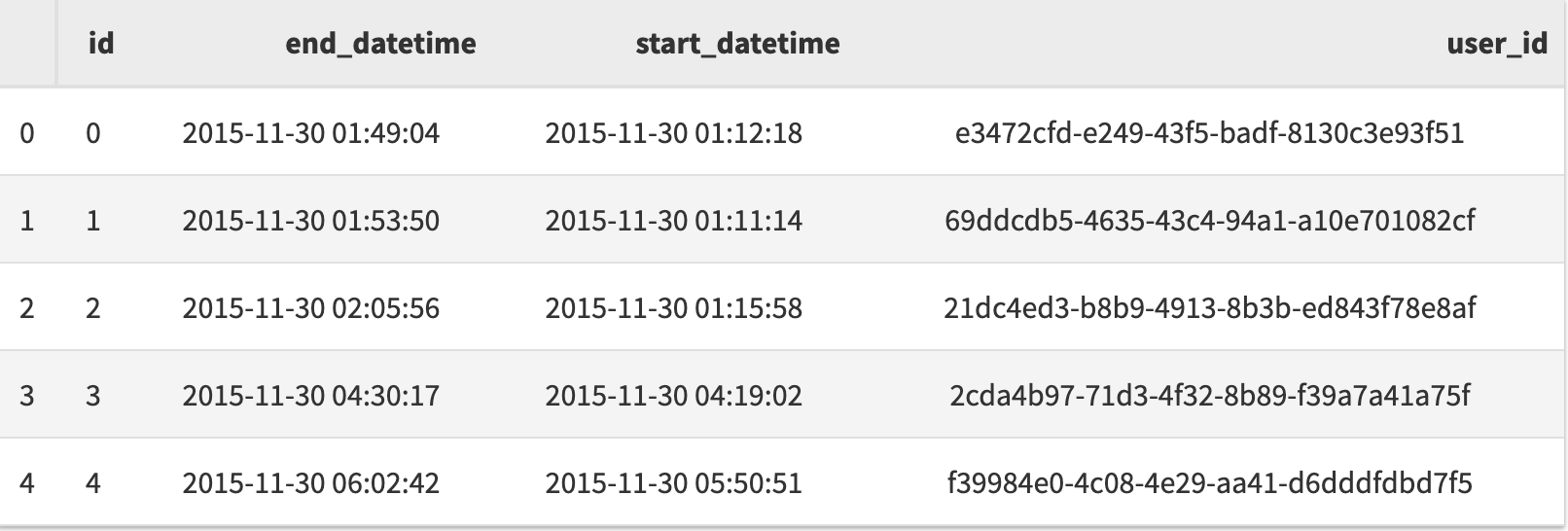
每行都有一个索引,默认为整数。你也可以将其他唯一数据列设置为索引。
加载数据
通过文本文件
通过 from_csv5 方法可以轻松加载 CSV 文件。
##从 0.21.0开始不推荐使用 from_csv,开始使用 read_csv,下边都是以 read_csv 作为例子
df = pd.read_csv('my_csv_file.csv')
你可以设置一些有用的参数来帮助处理不同的情况:
sep-定义文件中使用的列分隔符(例如:\t 代表 tab,|),默认值为逗号(,);
parse_dates-指定包含日期的列或者列数组 ,pandas 将尝试转换列中数据的数据类型为 date time - 这将更好轻松地进行基于日期的分组(例如按年份或月份分组);
header=None- 如果数据文件没有表头,请使用此选项。name 参数用于设置每列的名称,例如names=["col1", "col2", "col3"];
因此,加载更复杂的包含上述样本数据的制表符分割文件的实例如下所示:
df = pd.read_csv('my_csv_file.txt', sep='\t' header=None, names=['id', 'end_datetime', 'start_datetime', 'user_id'], parse_dates=['end_datetime','start_datetime'])
来自数据库
使用 from_sql 方法从数据库读取数据也相对比较容易。当然,你需要能够访问数据库并能够编写 SQL 语句来定义你想要的数据。这是一个使用 mysql.connector 模块直接从数据库中读取会话数据的实例。
import mysql.connector
# 创建一个数据库连接
conn = mysql.connector.connect(host='hostname',database='db_name',user='user_name',password='xxxxxx')
# 定义将提取数据的 SQL 查询语句
sql = "SELECT * FROM sessions"
# 创建包含查询结果的 DataFrame
df = pd.read_sql(sql, conn, parse_dates=['start_datetime', 'end_datetime'])
df.head()
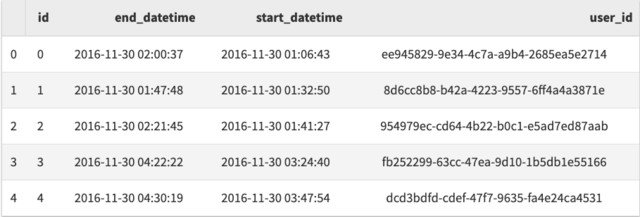
我只是以 MySQL 为例,假设你有正确的数据库模块可用并加载,你可以使用相同的语法轻松地从 SQLite ,MS SQL Server 或者 PostgreSQL 获取数据。
显然,直接从数据库读取的优势有两个:
- 如果你了解 SQL 语句,则可以在数据加载到 Python 之前进行一些过滤和数据操作。
- 假如你的数据库经常更新,它很容易刷新并重复你的分析,以获取关于你的数据的最新分析结果。
虽然上面的第一点是正确的,但是 Python 的一个优点是很多数据操作都发生在本地计算机的内存中,因此可能比大型或者低速数据库上的某些数据库操作更快。
带参数查询
根据你正在执行的操作,你可能希望将参数传递给查询。有一种很好的方法可以做到这一点,而不必将 SQL 作为字符串搞乱。
# 使用参数占位符定义 SQL
sql = "SELECT * FROM sessions WHERE YEAR(start_datetime) = %s"
# 使用提供的参数提取数据
df = pd.read_sql(sql, conn, parse_dates=['start_datetime', 'end_datetime'], params=[2018])
df.head()
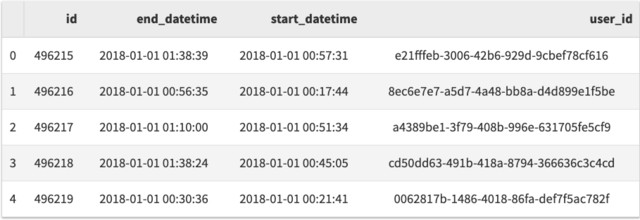
当然,你可以在查询中包含多个参数,只需要通过 params 数据传递更多参数。
来自现有的 Python 变量
最后,你可能还需要一些现有的 Python 数据结构作为 DataFrame 使用。pandas 提供了一种通过 form_dict6 将 Python 字典加载到 DataFrame 的简单方法:
my_dict = [
{'id': 0, 'name':'Bob', 'age':64},
{'id': 1, 'name':'Sally', 'age':61},
{'id': 2, 'name':'June', 'age':32},
{'id': 3, 'name':'Nish', 'age':41},
{'id': 4, 'name':'Lexi', 'age':25}
]
df = pd.DataFrame.from_dict(my_dict)
df.head()
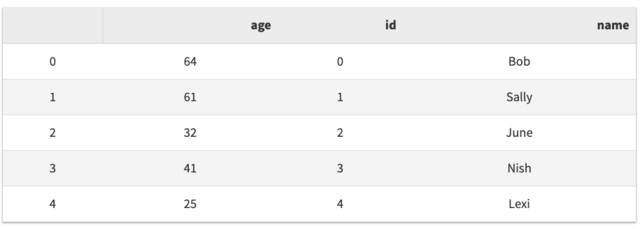
头部还是尾部
你可能注意到使用df.head() 来显示 DataFrame 中的数据摘要。好吧,你已经猜到了,但是df.head()只显示了 DataFrame 前5 行的摘要,如果你要想看最后五行,那么可以用df.tail()。你还可以设置要查看的行数df.head(n=10)
DataFrame 分类
当然,处分是按照某种顺序,否则前 5 和后 5 都毫无意义!
df.sort_values('start_datetime').head(n=3)
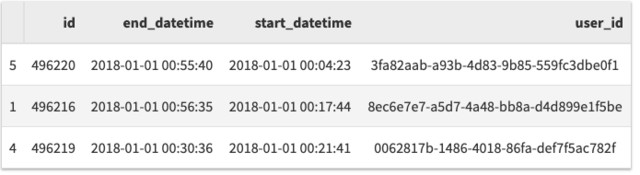
默认情况下,它将按升序排序。为了解决这个问题,我们可以这样做:
df.sort_values('start_datetime', ascending=False).head(n=3)
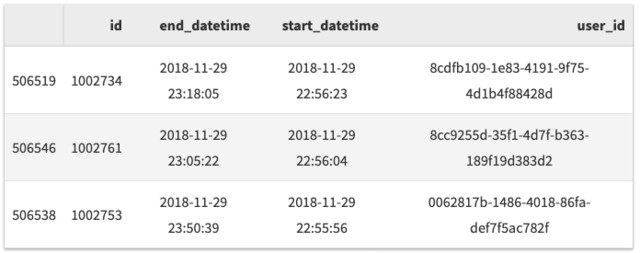
最后,你可以通过传递数组来基于多个列来进行排序:
df.sort_values(['start_datetime', 'user_id']).head(n=3)
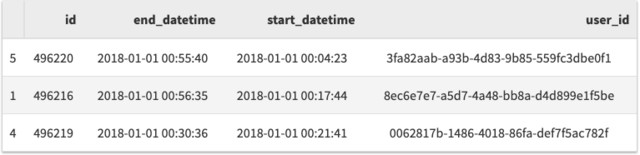
过滤数据
另一个常见操作就是根据列值来过滤数据:
df[df['user_id']=='8ec6e7e7-a5d7-4a48-bb8a-d4d899e1f5be'].head()
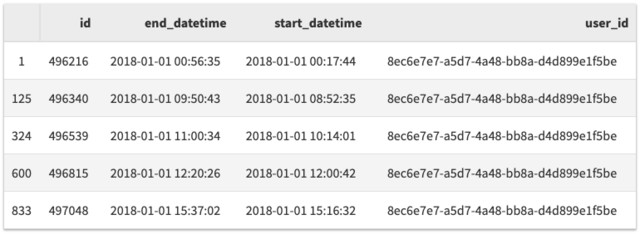
还记得当我们加载数据时,我们需要确保将数据中的日期解析为 datetime 么?那么,这意味着我们可以找到特定的月份和年份的所有会话,如下所示:
df[(df['start_datetime'].dt.month==10) & (df['start_datetime'].dt.year >= 2017)].head()
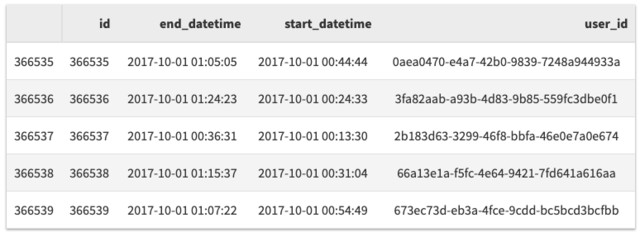
总结
好了,这里写了一些对于加载和研究数据的支持。下次我们将讨论分组、转换和连接数据!
如果你有任何意见、建议或者要求,请在评论中告诉我。
References
- https://productmetrics.net/blog/python-for-product-managers-part-2/: https://productmetrics.net/blog/python-for-product-managers-part-2/ ↩
- 第一部分: http://t.cn/ESz8gsO ↩
- 其它的样式: http://t.cn/RXGPp7u ↩
- DataFrame: %E4%B8%AD%E6%96%87%E9%87%8C%E7%BF%BB%E8%AF%91%E6%98%AF%E6%95%B0%E6%8D%AE%E5%B8%A7 ↩
- from_csv: http://t.cn/ESzucMx ↩
- form_dict: http://t.cn/ESzuao4 ↩