今年我开始更频繁地 vibe coding。
最直接的感受是,相比去年,各家 LLM 在写代码、改代码、理解项目上的能力都明显往前走了一步。不是那种发布会上听起来很厉害的进步,而是你真的把它放进日常工作里,会感觉“这东西现在能多干不少活了”。
工具也一下子多了起来。
我现在会根据不同任务,在 opencode、Claude Code、Codex、Kimi Code 之间来回切换。接下来可能还会试试 deepseek-tui 和 minimax code。
为了让自己对使用强度有个概念,我从 5 月 7 日开始用 Tokscale1 统计 token 使用量。
截至 6 月 7 日,刚好一个月,大概用了 2.5B Tokens。
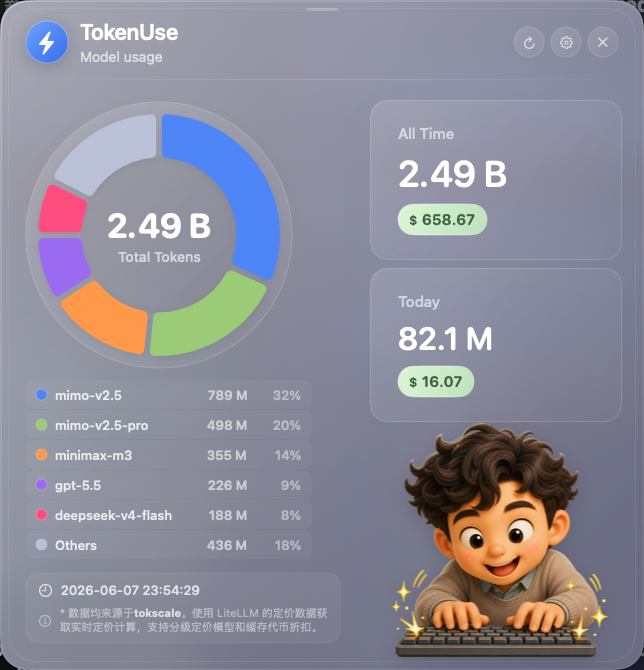
这个截图本身也是我 vibe coding 的一个小成果。它每天会告诉我,我到底用了多少 Tokens。
经常有人跟我聊,怎么才能对 AI 更有感觉。
我的体会是,可能不能只是偶尔遇到问题,去问一问“豆包”。
vibe coding 反而是一个让人更深入理解 AI 的办法。因为当你真的消耗一定量的 token,去做自己的事情、解决自己的问题时,如果你是一个还算喜欢思考的人,一定会开始发现新的问题。
然后你又会继续用 AI 去解决这些问题。
这个过程慢慢就转起来了。
这篇文章,其实也是这么来的。
如果只看表面,这像是一个“工具选择问题”:
哪个模型更强?
哪个 Agent 更聪明?
哪个 CLI 更顺手?
但我用下来,越来越觉得问题不只在这里。
当你开始同时使用多个 Agent,麻烦会从“哪个工具更好用”,慢慢变成另一个问题:
怎么让多个 Agent 在同一套上下文、规则和工作方式下稳定协作?
这也是我最近整理 agent.md2 这个项目时,一直在想的事。
它不是一个复杂项目。
甚至有点朴素:
用 AGENTS.md 做多 Agent 的主配置,用 CLAUDE.md 这类工具自己的入口文件做薄适配层,再把复杂、低频、可复用的流程沉淀到 SKILL.md。
听起来都是 Markdown 文件。
但我越用越觉得,这背后其实不是配置文件的问题,而是 Agent 使用到一定频率之后,必然会冒出来的管理问题。
从“能不能做”,到“能不能稳定做”
刚开始用 AI 编程工具时,我关注更多的是单次能力。
能不能写代码?
能不能改 bug?
能不能帮我总结文档?
能不能把一个需求拆成任务?
这些当然重要。
但使用频率上来以后,我开始在意另一类问题:
它会不会读错上下文?
它会不会改了不该改的文件?
它会不会每次都重新发明一套工作方式?
它会不会把一次性的偏好,当成长期规则?
它会不会在不同工具之间产生行为漂移?
这些问题,单靠模型更强,解决不了全部。
因为 Agent 面对的不是一道题,而是一个一直在变化的工作现场。
项目在变,工具在变,规则在变,人的偏好也在变。
如果没有稳定的上下文和边界,Agent 每次都要重新猜:
我是谁?
这个项目是什么?
哪些文件可以改?
哪些命令可以跑?
做到什么程度才算完成?
什么情况必须停下来问人?
所以我现在越来越觉得,多 Agent 使用的核心,不是把更多工具接进来,而是先给它们一个相对清楚的工作环境。
或者说,先把“你希望它怎么工作”这件事写下来。
为什么我把 AGENTS.md 放在主位置
在这个项目里,我把 AGENTS.md 放在主位置。
原因不复杂:它更适合做跨 Agent 的公共说明书。
不同工具有不同入口。Claude Code 常见的是 CLAUDE.md,Codex 会读取 AGENTS.md,其他工具也有自己的约定。
一开始我也是分开写。
结果很快就遇到一个问题:改了这个 Agent 的规则,忘了那个 Agent。
次数多了以后,我就开始琢磨,能不能让它们统一用一套“宪法”来干活。
如果每个工具都维护一份完整规则,短期看没什么问题,时间一长一定会漂。
今天改了 Claude 的规则,明天忘了同步 Codex。
某个项目新增了验证命令,另一个入口没有更新。
一个工具里写了安全边界,另一个工具里漏了。
这类问题不是“文档写得不够认真”,而是规则源头太多。
所以我更倾向于单源配置:
AGENTS.md是主规则,各工具自己的入口只做适配。
比如 CLAUDE.md 不需要复制一大段规则,只需要指向主规则,再保留少量 Claude Code 自己特有的补充。
这个做法不高级,但实用。
它解决的不是“怎么写得更优雅”,而是减少多工具长期使用时的规则漂移。
常驻规则不要写太胖
我之前也踩过一个坑:
一开始总想把所有东西都塞进 Agent 的常驻规则里。
写作偏好、项目背景、技术栈、Git 规范、代码审查流程、飞书操作方式、某个工具的 API 说明、某个项目的历史包袱……
最后规则越来越长,Agent 未必更稳定。
常驻规则太长以后,真正重要的边界反而容易被淹没。
所以我现在会把这些东西拆开看。
有些内容适合长期放在规则里,比如沟通偏好、Git 安全红线、文件修改边界、验证要求、高风险操作必须确认。
有些内容更适合放在项目资料里,比如项目用途、目录结构、技术设计、接口说明、开发计划。Agent 需要的时候按路径去读,不需要的时候就别一直塞在上下文里。
还有些内容适合做成 Skill,比如代码审查、规则漂移检查、项目初始化、文档回写、飞书知识库整理。
这些任务低频,但步骤多,容易出错。写成 Skill,比塞进常驻规则里更稳。
我现在的理解很简单:
常驻规则要短一点,复杂流程要结构化一点。
这样 Agent 反而更好用。
这不是提示词工程
很多人一提到 Agent 配置,会把它理解成“提示词怎么写”。
我觉得这只说到了一部分。
提示词当然有用,但当你真的把 Agent 用进日常工作,会发现更麻烦的是这些问题:
- 它从哪里读项目事实?
- 它怎么区分长期规则和临时指令?
- 它修改前要不要先理解上下文?
- 哪些动作算高风险?
- 失败以后要留下什么信息,方便下次继续?
- 多个 Agent 能不能共享同一套规则,而不是各用各的习惯?
这些更像工作流设计。
我做 agent.md,也是因为自己越来越频繁地在不同 Agent 之间切换。
有些任务 Claude Code 顺手,有些任务 Codex 顺手,有些场景可能未来会用 Kimi Code 或 opencode。
如果每换一个工具,就重新配置一次规则,长期一定不可维护。
所以这个项目不是想教大家写一个“万能 AGENTS.md”。
我更愿意把它看作一个实践样本:
把我自己长期使用 Agent 形成的规则、边界和工作方式,整理成一套可以迁移、可以维护、也可以继续修改的配置体系。
Agent 也会遇到现实世界的问题
我一直有一个判断:
很多技术问题,最后都会变成现实世界的问题。
AI Agent 也是一样。
单次演示里,一个 Agent 能完成一个任务,已经不稀奇。
真正麻烦的是长期使用:
它能不能在真实项目里稳定工作?
能不能遵守团队边界?
能不能理解项目历史?
能不能在多人、多工具、多仓库之间保持一致?
能不能把一次成功,变成下一次还可以复用的工作方式?
到这一步,就不是模型能力的单点竞争了。
它会进入流程、规则和知识管理。
从这个角度看,AGENTS.md、CLAUDE.md、SKILL.md 这些文件,看起来只是几个 Markdown 文件,实际上是在给 Agent 建立工作接口。
人需要 README。
Agent 也需要自己的 README。
而且这个 README 最好不要只写给某一个工具看。只服务单一工具,后面大概率还是会漂。
为什么把它开源出来
这个项目目前还很个人化,也不是什么标准答案。
我更愿意把它理解成一个持续整理中的工作台。
里面有我对多 Agent CLI 单源配置的理解,也有一些项目级模板和安装示例。
它适合的人,可能不是刚开始体验 AI 工具的人,而是已经开始同时使用多个 Agent,并且开始感受到这些麻烦的人:
- 配置漂移
- 上下文混乱
- 规则重复
- Skill 不知道该放在哪里
- 每个工具都有一套自己的脾气。
如果你也遇到类似问题,可以看看这个项目里的思路:
- 用
AGENTS.md做主规则源; - 用各工具入口做薄适配;
- 把项目事实放在项目自己的参考资料中;
- 把复杂流程拆成 Skill;
- 不要把所有东西都塞进常驻上下文;
- 定期检查规则是否过期、重复或冲突。
项目地址:
zhangsubo/agent.md3
它不会让某个 Agent 立刻变聪明。
但它可能会让多个 Agent 变得更可管理。
这件事听起来没那么性感,但我觉得挺重要。
因为 AI 工作流如果要从尝鲜走向日常,最后一定会碰到这些细碎的问题。
最后
我现在越来越觉得,AI 工具的竞争,表面上看是模型能力,往深了看,其实也是工作方式。
谁能更早把自己的知识、规则、流程和边界整理清楚,谁就更容易从 AI 里拿到稳定收益。
技术当然重要。
但技术进入真实工作以后,难点经常会换一种形态出现:业务是否愿意用,团队是否理解,规则是否允许,流程是否接得住。
Agent 也是这样。
这只是我最近一段时间的观察。
很多事情还在变,答案也没到定下来的时候。
但至少现在,真实使用已经开始给 Agent 提出更具体的问题了。