原文标题:PYTHON FOR PRODUCT MANAGERS - PART 3: GROUPING, AGGREGATING AND SUMMARISING
原文地址:ht tps://productmetrics.net/blog/python-for-product-managers-part-3/
原文作者:Joshua
翻译:张小璋 Sylvain Zhang

这是向你介绍 Python 的一系列文章中的一部分,并探索它如何帮助你更容易的完成产品经理的工作。在本系列的第一部分中,我们研究了如何安装 Python、设置 Jupyter Notebooks 以及如何在数据分析工作流中使用 Python。在第二部分中,我们更详细的研究了 Pandas ,并加载和研究了一些数据。
现在,让我们开始操作和修改数据,看看我们能学到什么。在这篇文章中,我们将着眼于对数据进行分组和聚合,总结数据,将数据连接在一起,并根据我们的目的对数据进行重构。
关于这里的例子
与前面的文章一样,我们需要处理一些来自 SaaS 站点的一些假设 session。基本数据如下:
数据分组
目前,我们的 dataframe 里每个 session 有一行。我们可以将其分组回答诸如「每个用户有多少 session?」或者「每月有多少次 session?」
Pandas 有一个 groupby 的方法可以完成这个需求。我们可以指定指定按哪一列进行分组,以及应用聚合函数。常见的聚合函数有count、mean和median。
通过分组,我们创建了一个具有不同形状的 dataframe 。虽然我们的源 dataframe 每个 session有一行,但分组将创建一个新的 dataframe ,每个唯一值对应以一行指定列。这个新的 dataframe 可以像任何其他的 dataframe 一样用于探索和可视化数据。
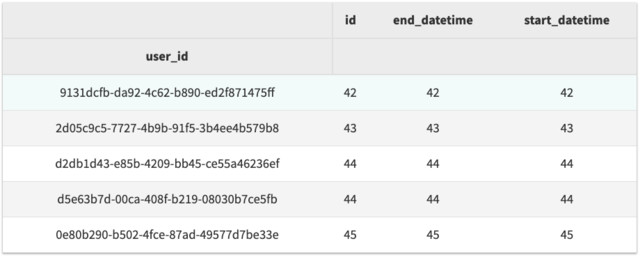
# 每一个用户有多少 sessions ?
df.groupby(df.user_id).agg('count').sort_values('id').head()
因为我们 session 的 start_datetime 被解析为 datetime 对象,所以我们可以使用特殊函数来查看日期的元素,例如:day, dayofweek, month, year 等。因此,按月分组,我们可以执行以下分组:
# 每个月有多少 sessions
df.groupby(df.start_datetime.dt.month).agg('count')
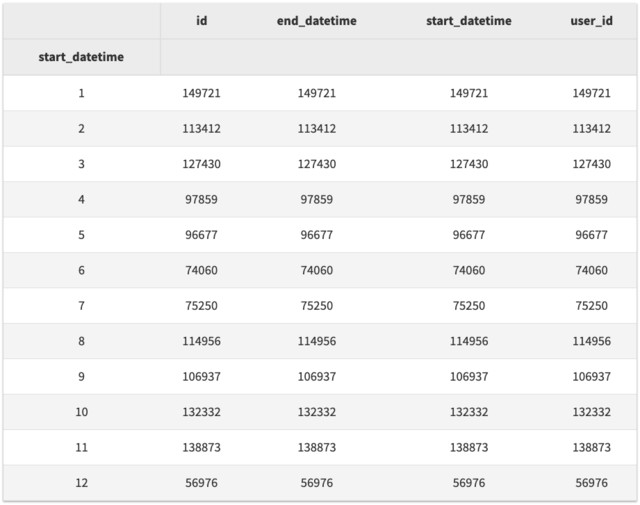
现在,注意上边的例子可能不是我们想要的——我们是为了计算一年中每个月的每列数量——但是结果只有12行。我们需要按照两个数据项进行分组,因此让我们按年份和月份进行分组,以查看随时间变化的 sessions 的数量。Groupby 方法支持用数组来进行分组,并按指定的顺序使用它们。
#每一年的每个月有多少sessions
df.groupby([df.start_datetime.dt.year, df.start_datetime.dt.month]).agg('count').tail(n=24)
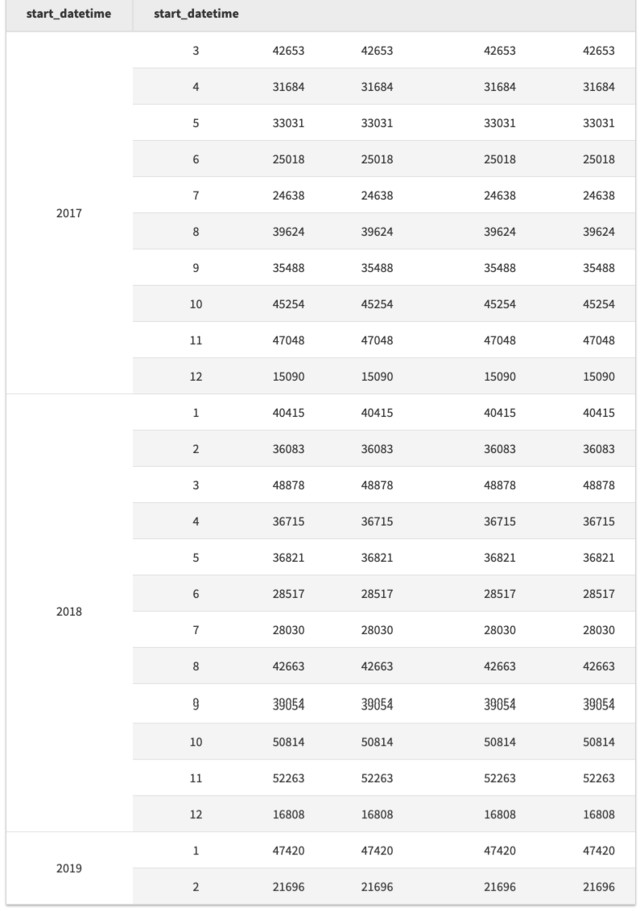
这就是计算的结果。接下来让我们看看平均数据。
首先,让我们计算每个session 的长度。同样,因为我们的开始和结束时间都是 datetime 对象,所以 Pandas 让我们的工作变得简单,可以对其进行特殊处理:
# 计算每个 session 的长度
df['session_duration'] = df.end_datetime - df.start_datetime
你只需要使用均值方法即可找到任何列的平均值。还有中位数以及最大值和最小值的方法。
# 现在看下 session 持续时间的一些统计数据
print(df['session_duration'].mean())
print(df['session_duration'].median())
print(df['session_duration'].min())
print(df['session_duration'].max())
0 days 00:34:02.443117
0 days 00:33:57
0 days 00:00:01
0 days 01:45:53
要查看 sessions 的平均长度是如何随时间变化的,我们可以使用在这里学到的所有知识,并将平均值与分组结合起来。不过,首先我们需要用数字来表示sessions长度——所以让我们用 numpy 库将其转化为秒数。
import numpy as np
# 以秒为单位计算 session 持续时间
df['session_duration_seconds'] = df['session_duration']/np.timedelta64(1,'s')
# 年和月的平均 session 持续时间(以秒为单位)
df[['session_duration_seconds']].groupby([df.start_datetime.dt.year, df.start_datetime.dt.month]).agg('mean').tail(n=12)
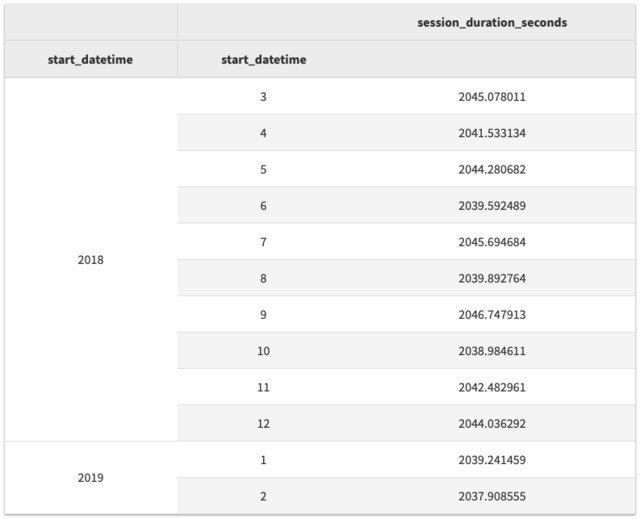
如果我们想要以分钟为单位,我们这样就可以了,当然这不是很准确。我们只需要修改一个字符!
# 以分钟为单位计算 session 持续时间
df['session_duration_seconds'] = df['session_duration']/np.timedelta64(1,'m')
简单!
数据描述
在上边的实例中,我们使用 dataframe 的一些方法来查看 session 持续时间列的均值、中位数、最大值和最小值。Pandas 提供了一个有用的实用程序,可以快速查看名为 describe 的 dataframe 这样的统计信息。
df['session_duration'].describe()
count 1284483
mean 0 days 00:34:02.443117
std 0 days 00:14:49.732860
min 0 days 00:00:01
25% 0 days 00:23:51
50% 0 days 00:33:57
75% 0 days 00:44:06
max 0 days 01:45:53
Name: session_duration, dtype: object
它对于快速处理你正在使用的数据非常有用。
将 PANDAS DATAFRAMES 集合在一起
有时候你不能拿只用一个数据集就回答所有的问题。你需要将数据组合在一起,以便提供更多的信息。
在 sessions 的基础上,让我们引入更多关于用户的信息。在 sessions 数据中有一个 user_id 。我们也有一些关于每个用户的数据:
- 他们的唯一 ID
- 角色(用户/管理员)
- 部门
和我们之前的数据一样,让我们把他加载并查看这些数据:
# 从制表符分隔的文本文件加载用户数据
user_df = pd.read_csv('users.csv', sep='\t')
user_df.head()
现在,要将数据组合,我们需要一个公共列——一个可以用来匹配 sessions 的数据。我们希望将 users_df 中的用户信息连接到主 dataframe 。我们可以使用 Pandas 的 join 方法来实现这一点:将一个 dataframe 连接到另一个 dataframe,从而创建第三个 dataframe。
# 将 sessions 数据将入用户数据
full_df = df.join(user_df, rsuffix='_user')
full_df.drop('user_id_user', axis=1, inplace=True)
full_df.set_index('id', inplace=True)
full_df.head()
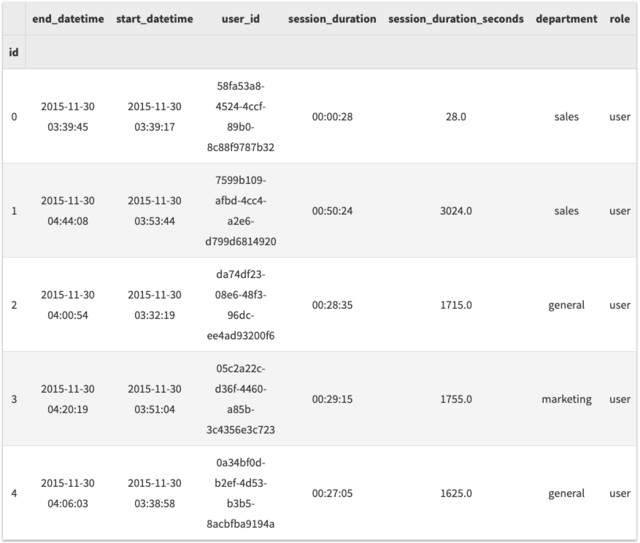
因为两个 dataframes 共享一个具有相同名字(user_id)的列,所以使用 rsuffix 参数来确保生成的 dataframe 中的每一列都有一个唯一的名称——如果需要,也可以使用 lsuffix 。因为我们不需要具有相同值的两列,所以可以删除冗余的副本。我还告诉 Pandas 使用 id 列作为 dataframe 的索引——它是 session 的唯一 id,因此在数据中是唯一的。
如果你习惯使用 SQL,你讲对这些非常熟悉。Join 方法接受一个「how」参数来指定你想要的连接类型(内部连接、外部连接等)。
现在我们已经加入了我们的数据,我们可以问一些更有趣的问题,比如:哪个部门的sessions 最多?或者用户角色是否影响会话的平均长度?
-----下边是张小璋的话了-----
这个 Python 系列文章终于翻译完了,但是受限制于我可怜的英语水平以及并不熟练的 Python 能力,估计很多人看起来会云里雾里。如果有能力还是希望大家去看原文。
顺便再说几句, Python 教程有很多,比如菜鸟教程、廖雪峰等等。至于哪个教程好,我的水平有限没法评价。最近又看到GitHub 上有一个高 star 的项目——Python – 100天从新手到大师,目前已经近三万 star,这么多人点 star 水平应该不错吧。我准备最近开始看看,看看我 100 天能不能成为一个 Python 大师(哈哈哈,狂妄的笑。)——开玩笑啦,不过用三个月去学习一门语言也是值得的,尤其是 Python 这么优雅。